Bridge cascading with geo-location is back
Back in 2018 we first released cascaded bridges based on geo-location on meet.jit.si. Then in 2020 as we struggled to scale the service to handle the increased traffic that came with the pandemic we had to disable it because of the load on the infrastructure. And now it’s finally back stronger and better!
In this post we’ll go over how and why we use cascaded bridges with geo-location, how the new system is architectured, and the experiment we ran to evaluate the new system.
Why use cascaded bridges?
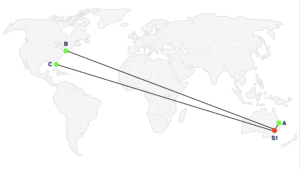
We want to use geolocation for the usual reason – connect users to a nearby server to optimize the connection quality. But with multiple users in a conference the problem becomes more complex. When we have users in different geographic locations, using a single media server is not sufficient. Suppose there are some participants in the US and some in Australia. If you place the server in Australia, the US participants will have a high latency to the server and an even higher latency between each other – their media is routed from the US to AU and back to the US! Conversely if you place the server in the US the Australian participants have the same issues.
We can solve this by using multiple servers and having participants connect to a nearby server. The servers forward the media to each other. This way the “next hop” latency is lower, and so is the end-to-end latency for nearby endpoints.
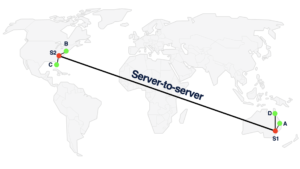
Architecture
There are many new things in our backend architecture!
1. JVB pools
We used to have shards consisting of a “signaling node” and a group of JVB (jitsi-videobridge, our media server) instances. In order to make bridges in different regions available for selection, we just interconnected all bridges in all shards. And this is exactly what broke when we had to scale to 50+ shards and 2000+ JVBs.
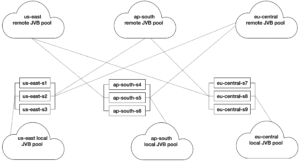
In the new architecture JVBs are no longer associated with a specific shard. A “shard” now consists of just a signaling node (running jicofo, prosody and nginx). We have a few of these per region, depending on the amount of traffic we expect. Independently, we have pools of JVBs, one pool in each region, which automatically scale up and down to match the current requirements.
In addition we have “remote” pools. These are pools of JVBs which make themselves available to shards in remote regions (but not in their local region). For example, we have a remote pool in us-east which connects to signaling nodes in all other regions. This separation of “local” vs “remote” pools is what allows us to scale the infrastructure without the number of cross-connections growing too much
As an example, in the us-east region (Ashburn) we have 6 signaling nodes (“shards”) and a pool of JVBs available to them. This is the us-east “local” pool. We also have multiple “remote” JVB pools connected to the shards — one from each of the other regions (us-west, eu-central, eu-west, ap-south, ap-northeast, ap-southeast). Finally, we have a us-east “remote” JVB pool connected to shards in all other regions.
2. Colibri2 and secure octo
In late 2021 we completely replaced the COLIBRI protocol used for communication between jicofo and JVBs. This allowed us to address technical debt, optimize traffic in large conferences, and use the new secure-octo protocol.
In contrast to the old octo protocol, secure-octo connects individual pairs of JVBs. They run ICE/DTLS to establish a connection, and then use standard SRTP to exchange audio/video. This means that a secure VPN between JVBs is no longer required! Also, we can filter out streams which are not needed by the receiving JVB.
3. Region-group selection
In the experiments we ran in 2018 we found that introducing geo-located JVBs had a small but measurable negative effect on round-trip-time between endpoints in certain cases. Notably endpoints in Europe had, on average, a higher RTT when cascading was enabled. We suspected that this was because we use two datacenters in Europe (in Frankfurt and London) and many endpoints have a similar latency to both. In such cases, introducing the extra JVB-to-JVB connection has almost no impact on the next-hop RTT, but increases the end-to-end RTT between endpoints.
To solve this problem we introduced “region groups”, that is we grouped the Frankfurt and London regions, as well as the Ashburn (us-east) and Phoenix (us-west) regions. With region groups, we relax the selection criteria to avoid using multiple JVBs in the same region group.
As an example, when a participant in London joins a conference, we will select a JVB in London for them. Then, if a participant in Berlin (closer to Frankfurt than London) joins we will use that same JVB in London instead of selecting a new one in Frankfurt.
Experiment and results
The new meet-jit-si infrastructure allowed us to easily perform an experiment comparing the case of no bridge cascading (control), cascading with no region groups defined (noRG) and cascading with region groups (grouping us-east and us-west, as well as eu-central and eu-west). We had 3 experimental “releases” live for a period of about two weeks, with conferences randomly distributed between them and the main release. We measured two things: end-to-end round trip time between endpoints and round-trip-time between an endpoint and the JVB it’s connected to (next-hop RTT).
By and large the results show that cascading works as designed and the introduction of region groups had the desired effect.
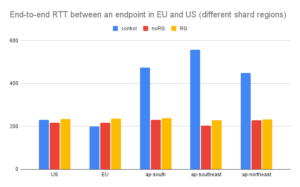
With cascading we see significantly lower end-to-end RTT in most cases. When the two endpoint are in the same region:
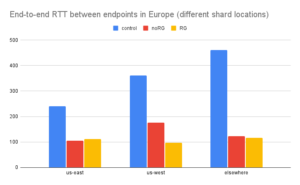
When the two endpoints are in different regions we see a slight increase when region groups are used, but the overall effect of cascading is positive.
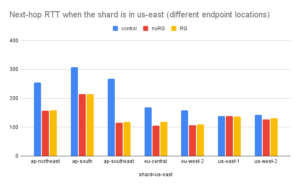
The next-hop RTT is also significantly reduced with cascading. Overall we see a 29% decrease (from 223 to 158 milliseconds) when the endpoint and server are (were) on different continents.
You can see the full results here.