Improving performance on very large calls: introducing SSRC rewriting
In the last stable release, Jitsi enabled a new feature called SSRC rewriting that improves the system performance for very large calls. This feature helps reduce the overall load on the system by reducing the number of signaling messages that get exchanged during a large call involving hundreds of endpoints. It also reduces the load on the local endpoint drastically by restricting the number of audio and video decoders created by the WebRTC engine thereby offering a better user experience for large calls.
When this feature is enabled, only a fixed set (let’s say up to 50) of SSRCs are signaled to the downstream endpoints in the call irrespective of the call size. An SSRC is nothing but a unique ID used for identifying a stream of RTP packets that belong to an audio or a video source. When additional media sources are requested by the receiver, the Jitsi Videobridge (JVB) overwrites the SSRCs of the newly requested media streams with that of the ones that were already signaled to the client before and are no longer needed. Therefore, no more than 50 SSRCs need to be signaled to the endpoints even if the number of media sources that will be routed in total far exceeds the set limit.
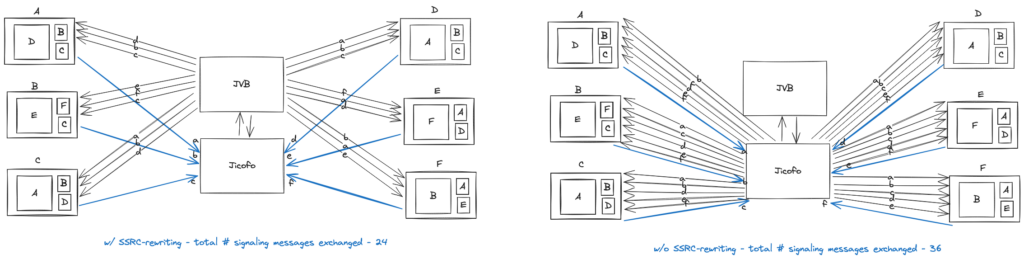
Moving on to the why – what is the problem that we were trying to solve by implementing SSRC rewriting?
The challenges that we faced when adding support for very large calls with respect to source signaling with the existing approach of signaling every new source to every other participant in the call were two fold.
At the client level, the number of m-lines in the SDP grew linearly with every remote source that got added to the call irrespective of whether media for that particular source gets routed to the endpoint or not. When a new m-line with SSRC is added to the remote SDP, the libwebrtc engine creates a transceiver and does all the plumbing necessary to decode a media stream with the given SSRC if and when it starts receiving it from the JVB. This tied up resources on the local endpoint unnecessarily and introduced delays in renegotiation cycles which resulted in unpleasant user experience. The client can also hit transceiver and SDP parser limits imposed by the browser resulting in unexpected behaviors. These performance issues are more pronounced on mobile endpoints which have fewer resources to begin with compared to the endpoints running on desktops.
On the backend, as the number of participants grew, so did the number of audio and video sources that needed to be signaled to every other participant in the call. This made the signaling traffic from prosody (XMPP communication server) to the endpoints grow quadratically. This was a problem, because Prosody, which is single-threaded, was already the bottleneck when scaling calls. Previously we had to introduce artificial delays in signaling in order to reduce the load. This caused long delays for the media to be established across participants when they unmuted their audio or video for the first time and was very disruptive to large meetings.
The solution to both of these problems was to switch to a demand based signaling mechanism where only a limited number of remote audio and video tracks are signaled to the endpoints depending on what is being needed or requested by them in real time instead of signaling all the known media sources in the call as and when they get added to the call.
Implementation in Jitsi Videobridge
Jitsi Videobridge (JVB) uses a slightly different approach for audio and for video when determining what sources to forward. Forwarding decisions for audio are based simply on the “loudness” of the streams determined from the audio level RTP extension.
With SSRC rewriting, JVB uses a separate SSRC space for each receiver. It maintains a map from an SSRC number to the name of a source. Changes to the map are signaled to the receiver over the direct signaling channel (a WebRTC DataChannel over SCTP), using partial updates:
[modules/RTC/BridgeChannel.js] <e.onmessage>: Received AudioSourcesMap: [{"source":"fc63db0f-a0","owner":"fc63db0f","ssrc":2602882473},{"source":"449360a0-a0","owner":"449360a0","ssrc":1358697798}]
[modules/RTC/BridgeChannel.js] <e.onmessage>: Received VideoSourcesMap: [{"source":"e01f2103-v0","owner":"e01f2103","ssrc":3129389873,"rtx":3219602897,"videoType":"CAMERA"},{"source":"9ac8fef2-v0","owner":"9ac8fef2","ssrc":1542056973,"rtx":1571329554,"videoType":"CAMERA"},{"source":"ed6b60f5-v0","owner":"ed6b60f5","ssrc":550523896,"rtx":2808127984,"videoType":"CAMERA"}]When a new stream needs to be forwarded, it is allocated an SSRC. Before the limit is reached, JVB simply generates a new SSRC number, and when the limit has been reached the oldest entry is reused. Let’s look at an example to make this more clear. Assume the limit is set to just 3, and the available sources are A, B, C, D, E. Initially the map is empty. When A starts sending packets, we allocate SSRC 101 to it and signal it to the receiver like this:
AudioSourcesMap: [{"source":"A","owner":"endpoint-A","ssrc":101}]Similarly when B and C start to speak we allocate SSRCs 102 and 103 for them:
AudioSourcesMap: [{"source":"B","owner":"endpoint-B","ssrc":102}]AudioSourcesMap: [{"source":"C","owner":"endpoint-C","ssrc":103}]Now we have reached the limit of 3 SSRCs. When D starts to speak, we’ll find the source in the map that has been active least recently (let’s say that’s B) and re-use its SSRC for D. We’ll signal an update (“SSRC 102 now belongs to D”):
AudioSourcesMap: [{"source":"D","owner":"endpoint-D","ssrc":102}]The scheme is identical for video, except the forwarding decisions are made in a different way. Receivers explicitly signal their preferences using video constraints. The source names and their mute status are published in presence when an endpoint signals its source information to the Jitsi Conference Focus (Jicofo) and therefore this information is already available with all the other endpoints in the call. Based on the current layout in the UI and the user’s preferences, the client sends the updated receiver video constraints over the bridge channel.
A bandwidth allocation algorithm in the JVB then decides which streams to forward to a particular receiver, based on its constraints and current network conditions:
[modules/RTC/BridgeChannel.js] <Fa.sendReceiverVideoConstraintsMessage>: Sending ReceiverVideoConstraints with {"constraints":{"ed6b60f5-v0":{"maxHeight":360},"e01f2103-v0":{"maxHeight":360},"9ac8fef2-v0":{"maxHeight":360}},"defaultConstraints":{"maxHeight":0},"lastN":-1,"onStageSources":[],"selectedSources":[]}Implementation on the receiver side in the client
On receiving an update to one of the maps (audio or video), the client adds the signaled SSRCs to the remote description on the peerconnection. The browser then fires a track event for each of the SSRCs, the corresponding remote tracks are then added to the HTMLElements associated with the remote user.
So when the audio packets with this SSRC arrive, the browser starts decoding the media and plays it through the selected audio output device. If the SSRC is already in use (i.e. the limit on the bridge has been reached) the client updates the owner of the associated track so that it gets attached to the corresponding HTMLAudioElement and the audio switches over to the new speaker seamlessly.
The video track creation process is the same as that of the audio tracks as described above. The client application needs to update the track’s owner whenever there is an updated source map involving the SSRC that is assigned to the track and re-attach it to the corresponding HTMLVideoElement so that the correct video stream is rendered in the remote participant’s viewport.
Challenges
But wait, re-using an SSRC like this is okay for audio because the streams simply get mixed before playback, but what about video, how do we avoid video content being rendered in the wrong viewport when signaling and media race? That’s the elegance of this approach, we simply use a large enough limit (larger than the maximum number of streams forwarded at any one time) and the occurrence becomes extremely unlikely. If the limit is larger by K, then K new forwarding decisions must be made before the signaling arrives at the receiver for the problem to happen.
So how do we choose the limits? We have the constraint just mentioned, but also an interesting trade-off. If the limit is too high we’re using unnecessary resources at the receivers. But if the limit is too low, we’ll be signaling updates more often. We have chosen to set the limits to 50 by default. That’s 50 for audio and 50 for video, which is well above the maximum of 25 tiles that we display at any time.
When SSRC rewriting is enabled, the number of source signaling messages can increase drastically based on the SSRC limits set for the conference and the total number of participants in the call. Imagine a call with 100 participants where everyone has their video on; UI shows a grid of 25 participants and the SSRC limit is set to 25. Whenever the user scrolls to the next grid of 25 participants, existing SSRCs get remapped. This happens everytime the user scrolls back and forth. This results in a lot of signaling messages over the bridge channel. What if the websocket connection for the bridge channel is down at this time? This would result in videos not being rendered or audio from new dominant speakers not being heard which can be very disruptive to meetings. All the sources are signaled immediately after the websocket connection reforms but even minimal disruptions to audio can be very annoying.
To mitigate these issues, Jitsi client switches to using WebRTC’s SCTP data channel for establishing the bridge channel instead of using a websocket. This ensures that the bridge channel is up and running all the time as long as the media connection between the client and the JVB is up. This results in minimal or no disruptions to the signaling messages from the JVB to the downstream endpoints.
Current status of the feature
This feature has been well tested and has been running on meet.jit.si for the past few months now, with limits set to 50. We also enabled it by default in our last stable release of the Debian packages and Docker images. We will be releasing it soon to all our production deployments in the next few releases pending investigation into some SCTP crashes that we are seeing in the JVB .
❤️ Your personal meetings team.